6 March 2005
Very long url strings do not insert a
carridge return in the browser and thus make the window much wider
than I want it to be while viewing. I suppose that I could insert
these into a link so that the informatin would be there for the savey
reader. But in a software development document it is often very
necesssary to have these long links as text so that the readers of
the document can see them at a glance. But the inclusion of these
into a web page makes the page annoyingly wide. This results in
scrollbars being far too wide. The page doesn't display well in this
case.
Here is a screen shot of how awful this
looks in my browser:
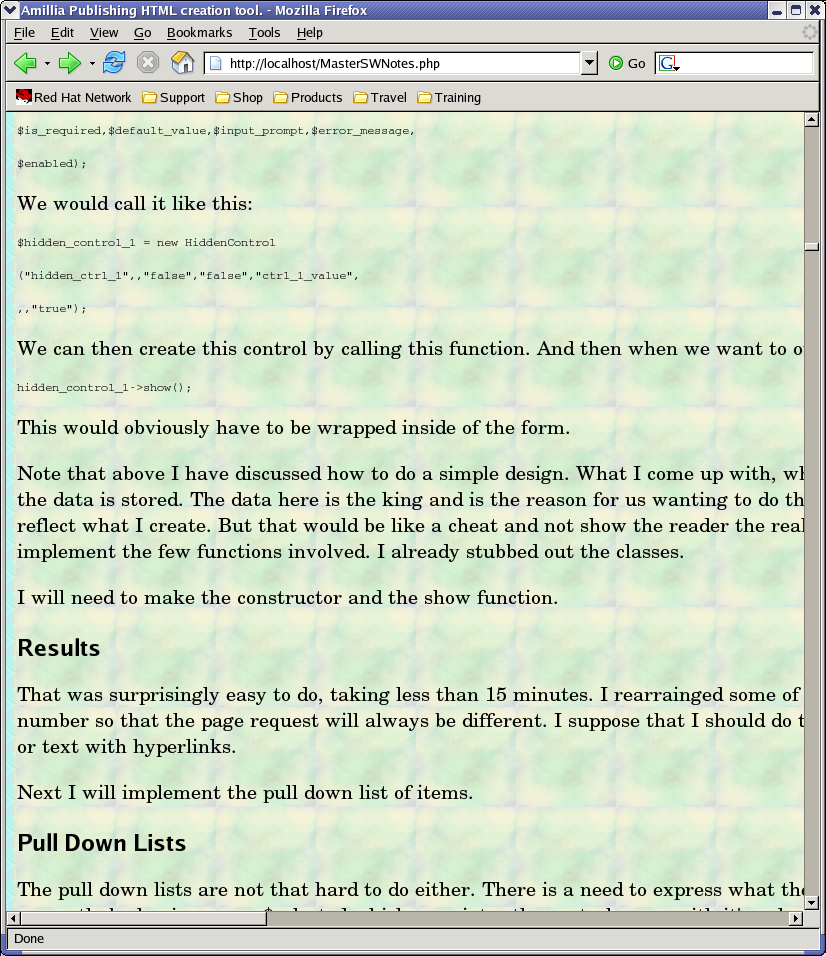
If
I display the file just as it is, not wrapped into a table like I do,
then it relays out the text for me as I resize the window, as I want
it to do. But I want it to be wrapped into a new page that is branded
and with links back to the main site. I suppose that I could see if I
can change the sizing of the table to be absolute.
I tried some different things and these
did not work. I probably need to go in and modify the file. Or I need
to strip headers off and do something else with this.
I modified my display script to add a
space after every amperstand so that the page will display more
properly. This provided a page that was more reasonable. However,
what does this do to every other amperstand on the page? It adds a
space! This would be a bad thing if this were a link with post data
in it!
I created a multi_file_png class that
wraps the various display of gallery functions. I need to modify
these so that they adhere better to my newer version things. This is
an example of how a legacy can be wrapped by a newer idea. Details
are available by viewing the code. There is no rocket science here.
Next I need to work on the form classes
and have them adhere to the Amillia Publishing Company Standard of
having a show function for a class.
Other important work: Logo heading.
I have worked on things and gotten a
very different looking page. I finally created the promised HTMLForm
class and made it work. It is incomplete in the sense that there is
more that forms can do than what I have implemented. However it is
currently a working interface that has ported well. One more step is
needed. This other step is to allow for the construction of the form
to also imply the data that is to be parsed.
The data that is passed over to the
server upon a post needs to be built into the links for each image.
That should be automatic, so that the system will easily accommodate
adding new post items.
Here is a screen shot of things now:
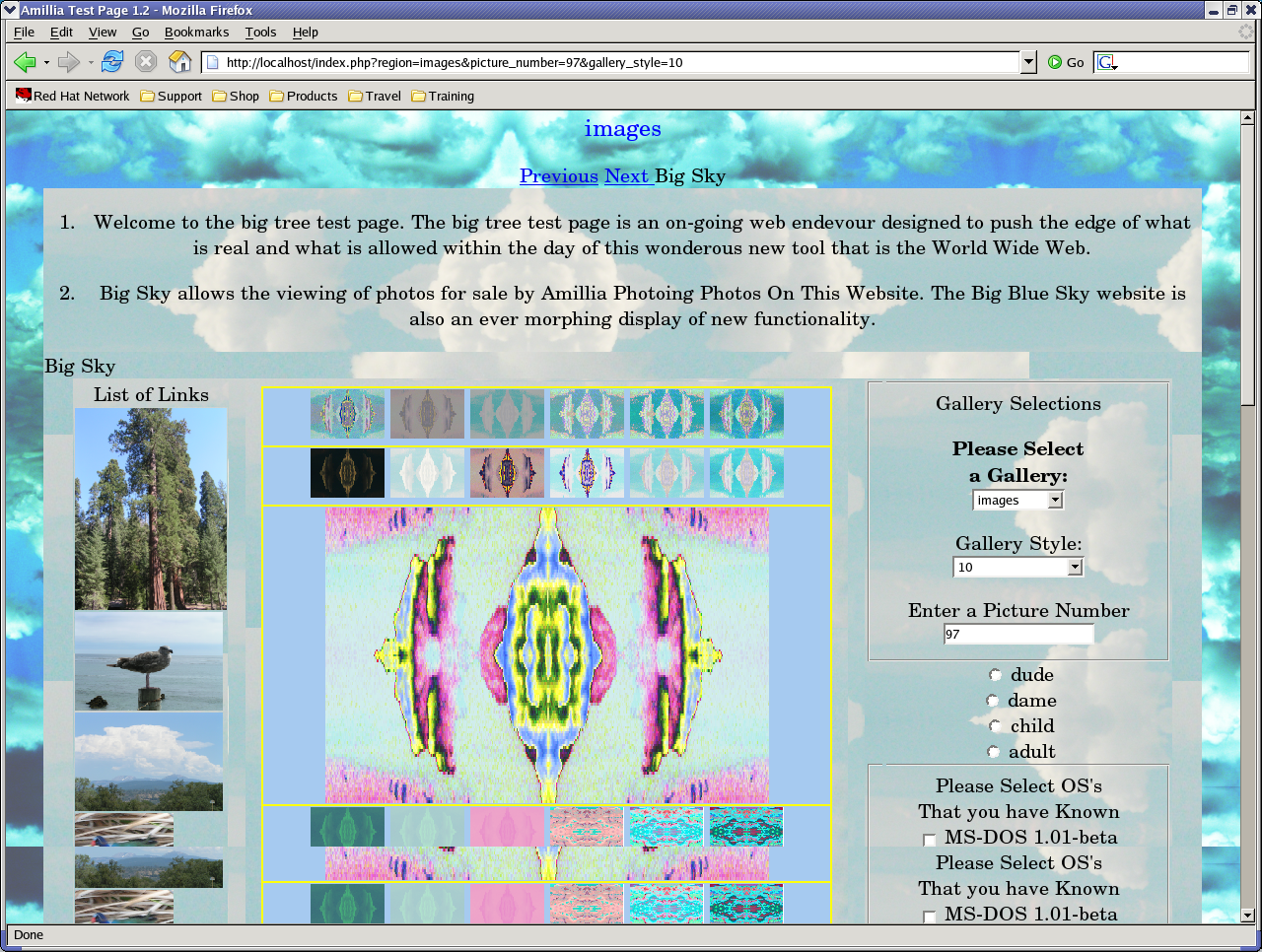
This is still not what I want to post
live on the Internet. But as you can see the form interface is now a
lot different in that is is on the right side, in the third coloumn
of one of the tables. The form is now showned by a call to show from
the page. The form interface seems to be working. I may want to add
some other possibilities to it, as I wouldn't mind having an image
map.
Right now when the page refreshes from
a click on one of the images or from a get gallery post, the page
jumps. This is because I have the paragraphs at the begining.
I need to implement some font choices
so that I can try different ones out.
Other important point: I want to have
the images on the images page show up sized correctly.
I want image data to appear with the
picture if desired.
I want to be able to edit and map the
image data.
March 10, 2005
Below there is a new screen shot:
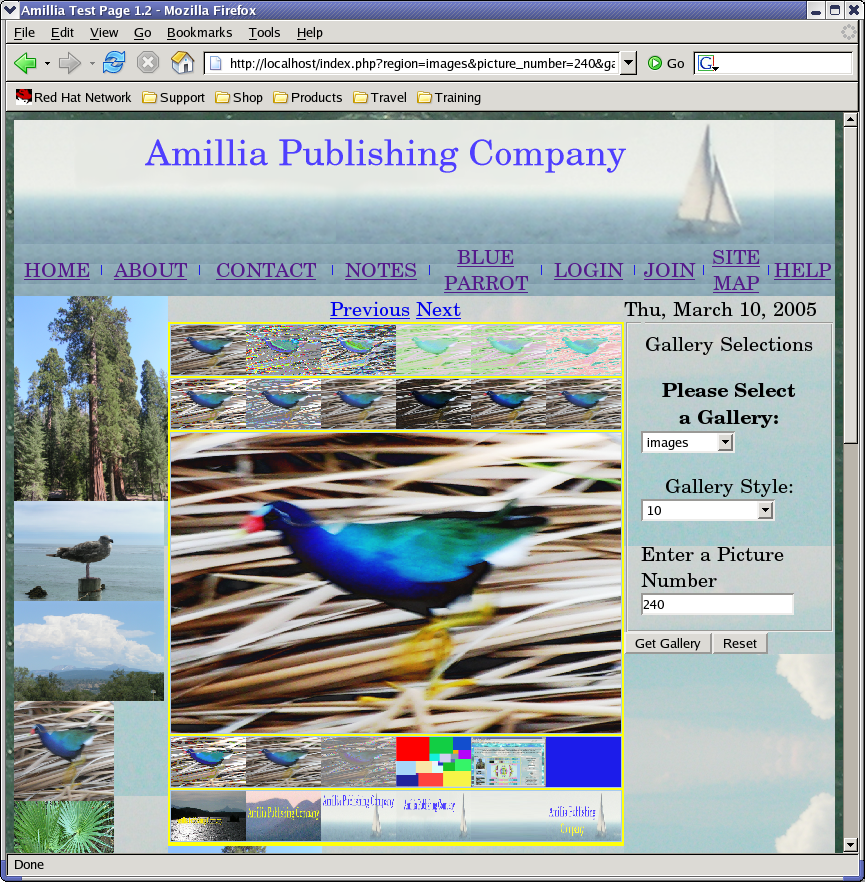
This needs work because I think that
the images are a little too big. Also the fonts on the menu bar a
little too large. More work to do.
I want to get sessions working so that
I can log in and then be one person or the other so that I can make
pages that differe through the input of the user. This new feature
needs the following parts:
1. The ability to toggle the features
of the page through post requests so that the page is different based
upon the needs of the user. this should happen in a way that a
user's session would persist and the user would go back to where he
or she had been before.
2. The ability to save features of a
page that are added by the user. This will also include the ability
to save and group page features that are created through php scripts.
3. Attribute editor is a need as that
allows the user a very easy way to modify a page.
4. Save/Restore.
Entity Loader
An Entity Loader will read a file and
then create the entities as needed. If the system has a session
casheing option, then it might be that the Entity Loader just
verifies that the entity is correct and that the user has the
authorization to view the request.
Entity Storing
The ability to store the entities
during a session so that various entities that persist accross the
visits to the page don't need to be recreated every time the page is
loaded. This advanced behaviour will result in faster page spawning.
This will be especially evident when a processor intensive load is
intiated.
Classes need a loader that reads the
data on the class from a file, group of files, or other URL based
input.
Output Emitters
Classes need the ability to emit
various output formats in addition to the html that they currently
will emit through their show function.
Classes can be fitted with various add
on functionality that will allow for the user to programmatically
toggle the functionality. These toggles can be simple addon boolean
classes.
Storage Formats
These Methods of storage of output are
already available:
PHP structure formats for loaded
entities
HTML
The following Storage Formats should be
quickly available:
Manage persistent session entities in
PHP memory.
XML
OpenOffice (which is a zipped xml
fileset)
Lazy Evaluation is a basic rule of PHP.
The ability to save the evaluation for the next time is a feature
that will be needed for a real site. However, if entities become
very large, then they will flood the memory. For this reason an up
and running site needs to manage the entities that it is handling and
keep track of how big they are.
Entity Profiling
A basic rule of embedded programming
for reliable systems is to have a profiler available and inventory
the memory requirements of the various software tasks.
The advanced issues of profiling to
allow for very large throughput from a single server are not a
necessary component of a successful website. If a site is
overwhelmed it is very common for a cached version to become
available later. When a site is taken down due to sudden and
unexpected traffic, then this can be a very annoying feature. But
this only happens when a site is suddenly featured on a web log or
comment board.
If a site is never considered to be for
high volume then the profiling is not a need. The sessions should
time out after a while. But also to avoid stack overflowwing there
needs to be a limit to how much memory a session can grab. A webot
could very easily produce a stack overrun for a system that allows
the user to add unbounded content. To avoid this there is usually a
'wow, cowboy' kind of answer to a request for a post of new material
if the user has done it very recently.
Any memory manager is overhead in a
system. Very simple optimazations can be added to try and avoid the
very embarassing slash-dot effect (/.). That is when a page is
posted in an article on Slash-dot and then all the readers of that
page rush to the ariticle and a lot of the time the page will go boof
and there will be an error spawned either by the server in question
or some other device that is routing traffic from that server.
Most web pages are not viewed like that
all at once. Many times a site will be very useful without a hitch.
When traffic increases it is a bad time to start worrying about how
to sure up your site. That is the time that you want your site or
page live and not crashing. That is when you need to have the server
keep serving.
How to add efficiency to a site
A lot of sites have a lot of various content. They run scripts
that create the output based upon what comes in as header data from
the URL: the POST or GET data. When that data comes in the page is
spawned from a script. Suppose that within that script that there
are various entities that are spawned everytime the page is viewed
and yet are always the same and not different. The script needs to
open some XML file, load it into memory, and then create the output
based upon what is in the XML file. And thus it creates some kind of
valid HTML output that it thus inserts inside of the enitity that
wraps the page itself. And everytime this happens the same exact
entity is created. Would it not be better to only do the generation
of the HTML formatted output once and somehow save it for the next
time? Obviously it would. And doing that we save a lot of cycles
and have a much faster site.
But do we have the resources to do this? Should we not first get
a working site? And yet if we plan for this eventuality, this
ultimate success, then we are also saying to ourselves that we
believe that what we are wanting to do is actually a useful endevour
and worthy of the effort whatever it takes.
And yet the trade off between time and effort and getting
something useful for a single person doing a website means that the
efficiency issues need to be considered, thought out, and then added
in a timely way. It is a shame to design an efficient system if the
efficiency doesn't matter.
It has always been my experience that efficiency as a design
concern is always prudent. Even if the efficiency is not needed yet,
it can be important to know how to make it appear later. A working
prototype is a wonderful thing. But to avoid the /. effect, one
needs a reliable and efficent web spawning system that doesn't just
recreate content over and over thus waste cycles.
But in the meantime while a site is low bandwidth this really
doesn't matter. I can say, therefore, that only at the time of a
site going hot by being referenced from a popular site is the
efficiency needed. Or to run a popular site it is also needed.
These are not trivial issues. And so to be a serious software
engineer you need to think about them.